一个RAG系统的实现
RAG
导言
我们在日常生活中遇到不知道或不清楚的知识可能会采取咨询他人、上网查询、压力AI,或者不知道算了…但如果是在工作环境中,这些办法也如都行不通。首先,许多公司内部的业务知识无法在网络上查到,这些东西一般就涉及公司机密了。AI也是同理,由于它们没有经过这些特定的内部知识的训练,同样无法有针对性的返回准确的回答。摆烂同样不行,这是任务和需求;咨询同事或许是一个好的办法,但是同事们也都有自己的事情要做,而且有的时候会收到这样的回答:“公司手册不是有吗?你认真一点吧,自己看看去!”。这句话说的很对,但许多人何尝不是看过文档发现
- 资料杂乱繁多不知道看哪一份资料;
- 长的资料手册也找不到对应问题的位置;
- 写资料的人表达能力有限,看不懂;
于是你就想,怎么不能打造一个业务的知识库,将业务所涉及到的知识和方法都放在里面,然后提供一个查询功能,我问它什么,它就回答什么不就好了?
啊哈,这就是本文所要介绍的 RAG 系统。(不是老鼠那个 RAT)
RAG (Retrieval Augmented Generation - 检索增强生成)是一种结合了信息检索和文本生成能力的人工智能范式。它旨在解决传统大语言模型(LLM)在知识时效性、事实准确性以及无法访问特定领域或最新信息等方面的局限性。
核心概念
要搭建 RAG 系统,首先需要了解以下几个关键概念:
- 大语言模型 (LLM): RAG 的核心是利用强大的 LLM 进行文本生成。LLM 拥有强大的语言理解、生成和推理能力,但其知识是基于训练时的数据,可能不包含最新或特定领域的信息,也可能“一本正经地胡说八道”(hallucination)。
- 外部知识库 (Knowledge Base): 这是一个包含丰富、最新或专业知识的数据源。它可以是文档集合、数据库、网页等。在 RAG 中,LLM 不再仅仅依赖其内部参数化知识,而是可以从这个外部知识库中检索信息。
- 检索器 (Retriever): 检索器的任务是从外部知识库中找出与用户查询最相关的信息片段(或文档)。这通常通过将查询和知识库中的文档转换为向量(Embedding),然后计算这些向量之间的相似度来实现(例如,使用向量数据库进行最近邻搜索)。
- 生成器 (Generator): 生成器就是 LLM 本身。在 RAG 中,LLM 接收的输入不再仅仅是用户查询,而是“用户查询 + 检索到的相关信息片段”。LLM 利用这些检索到的信息作为上下文,生成最终的答案。这使得 LLM 的回答更加有依据、准确,并能涵盖训练数据之外的新知识。
- 增强 (Augmentation): “增强”体现在 LLM 不再是孤立地生成内容,而是“被检索到的信息所增强”。检索器为生成器提供了实时的、外部的、可能更精确的事实依据,极大地提升了 LLM 的表现。
实现步骤
一个典型的 RAG 系统实现通常包括以下几个主要步骤:
- 数据准备与索引 (Data Preparation & Indexing):
- 文档加载 (Document Loading): 从各种来源(如
.txt,.md,.pdf,.docx, 数据库等)加载原始数据。 - 文档分割/分块 (Chunking): 将加载的长文档分割成大小适中、语义连贯的小片段(chunks)。这是关键一步,因为过大或过小的片段都会影响检索效果。常用的策略有固定大小分块、递归字符分块、语义分块等。
- 文本嵌入 (Text Embedding): 使用一个预训练的文本嵌入模型(如
SentenceTransformer模型)将每个文本片段转换为高维数值向量(Embedding)。这些向量捕获了文本的语义信息。 - 向量存储 (Vector Store): 将这些文本向量及其对应的原始文本片段存储到向量数据库(如 ChromaDB, Faiss, Pinecone, Weaviate 等)中。向量数据库能够高效地进行向量相似度搜索。
- 文档加载 (Document Loading): 从各种来源(如
- 检索 (Retrieval):
- 查询嵌入 (Query Embedding): 当用户提出一个问题(Query)时,使用与文档嵌入相同的嵌入模型,将用户查询也转换为一个向量。
- 相似度搜索 (Similarity Search): 在向量数据库中执行相似度搜索,找出与用户查询向量最相似的
Top-K个文档片段。这些片段被认为是与用户问题最相关的上下文。
- (可选)重排 (Reranking):
- 为了进一步提高检索的精确性,可以引入一个重排器(通常是 Cross-Encoder 模型)。
- 重排器会接收用户查询和初步检索到的
Top-K个片段,并对每个“查询-片段”对生成一个更精细的相关性分数。 - 根据这些分数,重新排序并选择
Top-N个(通常N < K)最相关的片段,以提供给生成器更精炼、更高质量的上下文。
- 生成 (Generation):
- 构建 Prompt (Prompt Construction): 将用户查询和经过检索/重排得到的
Top-N个相关文本片段组合成一个结构化的 Prompt。这个 Prompt 会明确指示 LLM 的角色、任务,并包含“基于提供的上下文作答,不要编造信息”等指令。 - LLM 推理 (LLM Inference): 将构建好的 Prompt 发送给大语言模型(如 Google Gemini, OpenAI GPT 等)。LLM 利用其强大的语言理解和生成能力,结合提供的上下文信息,生成一个连贯、准确的答案。
- 答案输出 (Answer Output): LLM 返回生成的答案,呈现给用户。
- 构建 Prompt (Prompt Construction): 将用户查询和经过检索/重排得到的
以下是一个简单的搭建原理图:
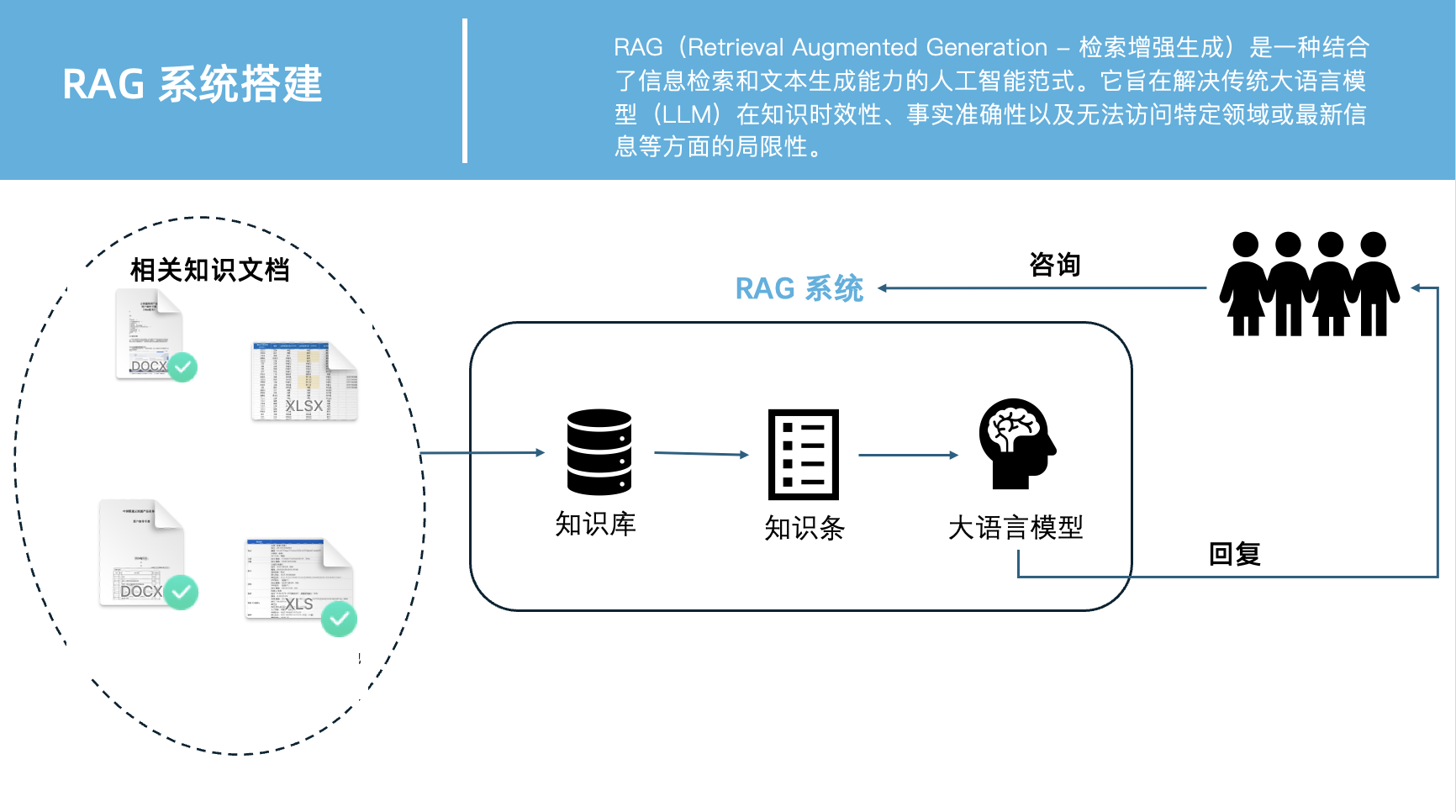
核心组件概览
- 知识库 (Knowledge Base): 你的云讯通内部资料(文档、FAQ 等)。
- 文档加载器 (Document Loader): 读取你的知识库文件。
- 文本分割器 (Text Splitter): 将长文档分割成小块(
chunks),方便检索。 - 嵌入模型 (Embedding Model): 将文本块和用户问题转换为向量。
- 向量数据库 (Vector Store): 存储所有文本块的向量,用于快速检索。
- 本地大语言模型 (LLM): 用于理解问题和生成答案。
- RAG 框架 (LangChain): 串联以上所有组件,简化开发。
Python 实现
1. 环境搭建
处理环境问题真的是想说:人难做,屎难吃。
1 | |
uv 介绍
uv 是由 Rye(由 Astro 框架的创建者 David Wadsley 开发)团队推出的一个高性能的 Python 包安装器和解析器。它旨在成为 pip 和 pip-tools 的超快速替代品。uv 由于使用 Rust 编写, 在执行依赖解析和包安装时比 pip 快 10 到 100 倍。这意味着更快的开发周期、更快的 CI/CD 构建时间。
包介绍
sentence_transformers
专注于将文本(句子、段落、甚至短文档)转换为高质量的向量(也叫“嵌入”或“embeddings”)。这些向量捕捉了文本的语义信息,使得语义相似的文本在向量空间中的距离也更近。chromadb
ChromaDB 是一个 开源的向量数据库 (Vector Database)。它是专门为存储、管理和搜索向量嵌入 (vector embeddings) 而设计的google-genai
google-genai是 Google 官方提供的用于与 Google Gemini 系列模型进行交互的 Python 客户端库。它是 Google AI Studio 和 Gemini API 的官方 SDKpython-dotenv
用于加载.env文件中的环境变量
获取 Google Gemini 接口ID
- 前往Gemini 官网注册获取。
- 创建文件
.env - 输入
GEMINI_API_KEY=xxx
2. 代码逻辑
1 | |
前后端搭建
使用 flask
后端(Flask API)
- 主流程已在 main.py 封装为 get_answer(question: str) -> str,实现了分块、嵌入、检索、重排、生成等RAG流程。
- API接口在 app.py,提供 /ask POST接口,接收 JSON 格式问题,返回智能问答结果。
- 欢迎页:根路径 / 支持 GET,返回欢迎信息。
- 端口:Flask 服务运行在 5001 端口。
前端(Streamlit)
- 文件:webui.py
- 功能:
- 顶部渐变标题与副标题
- 左侧:智能对话区(历史消息、输入框、发送按钮)
- 右侧:系统核心功能、技术架构、统计信息、FAQ快捷提问
- FAQ一键提问,自动调用后端API
- 对话历史自动刷新
- 兼容性:已将 st.experimental_rerun() 替换为 st.rerun(),适配新版
依赖管理
- requirements.txt 已包含 Flask、streamlit、requests、sentence-transformers、chromadb、python-dotenv、google-generativeai 等依赖。
启动与测试流程
后端启动
1
2source .venv/bin/activate
python3 app.py前端启动
1
streamlit run webui.py
下一步建议
- 可继续美化前端、增加对话清空、导出、用户登录等功能
- 可考虑部署到服务器,供团队或客户使用
- 可扩展知识库、支持多文档、权限管理等